Sometimes you have large data sets. Most of the time this makes Django slow.
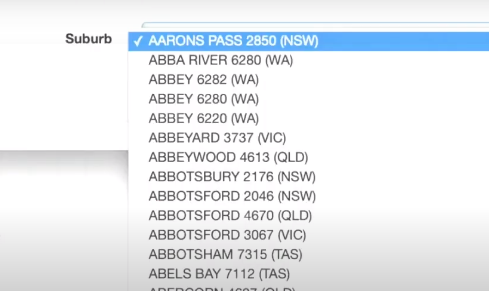
For example there are 17,000 suburbs in Australia – so having an address with a foreign key to suburb is going to create slowness in forms and in your admin. Carlton Gibson (who is a Django Fellow) goes through several options to speed up accessing large data sets in this DjangoCon talk.
Carlton uses large data sets and goes through examples in Django Filter, Django Rest Framework and the Django Admin.
It’s only 20 minutes for the talk and 10 mins for questions afterwards so grab a hot drink and have a watch:
I was lucky enough to provide the Australian Suburbs dataset to Carlton when he put a call out on twitter. I get a mention at 5:20!
Three strategies
Carlton suggests 3 strategies:
- Do Less
- Don’t repeat work
- Do the work early
Do Less
Here we look at ways to reduce the number of queries. We are introduced to our two friends:
select_related() – for Foreign Keys
prefetch_related() – for Many to Many
It is worth being familiar with these two functions. They reduce total SQL queries by saying to Django “I’ll need this field later – so please go and get it now”. Under the hood, Django is implements a join to the SQL query.
You may want to look at an addon like django-auto-prefetch which will do this for you.
Don’t repeat work
At around 16:20 Carlton discusses setting up a formset for admin. I must admit I was not familiar with this technique, so it is good to learn!
From what I can see, you are populating the choices only once for each record. This reduces the query load. I will be looking into this technique further in the near future.
Do the work early
18:40 brings us to ‘Do the Work Early’.
The idea being is that our sets don’t change that often, so we can cache data. Do your calculation then throw it in the cache.
Conclusion
It’s a great talk and one you should bookmark for when you next have performance problems on large datasets.